It happens in all complex web applications – the service you are operating goes down, and users are affected. In order to fix these outages, and prevent them from happening, software teams need to have some way of measuring “how bad” an outage is.
Metrics for “availability” – which is a measure how much of the time a site is “up” have been around for a while, but in the paper “Meaningful Availability” from Google’s Tamás Hauer, Philipp Hoffmann, John Lunney, Dan Ardelean, and Amer Diwan, the authors propose a new metric that more accurately measures availabilit.y
In the paper, the authors discuss current approaches to measuring availability and their drawbacks, in addition to explaining the value of the approach they are proposing.
I’ve personally only really had expososure to “count-based” metrics for measuring availability (Sucess Rates), so this paper was a great introduction to other approaches. It also does a great job of making clear that different applications have different needs in terms of how to measure availability.
Why does what metric we use matter?
In this paper, the authors discuss a few different metrics for measuring availability. But before diving into those, the authors describe qualities of a good availability metric, which can then be used to evaluate whether a metric is right for the task at hand:
- Meaningful: An availability metric should correspond to what users actually experience
- Proportional: A change in the metric should correspond to a proportional change in the user experience
- Actionable: The metric should give insight into why availability was low
Prior Art: What is “availability”?
The authors begin the paper by going through existing approaches to measuring availability.
Time-based Availability Metrics
A common way of measuring availability to use the ratio of the amount of time that a service was up. The standard formula for this is:
Here the MTTF is “Mean time to failure”, which means how long the service was running before there was an outage, and MTTR is “Mean time to repair”, or how long it took during an outage to resolve.
The main problem with using this is that it requires labeling periods as time as either outages or “not outages”, and in distributed systems, outages are usually partial. Because of this, the metric isn’t super meaningful, as there’s no way to distinguish here between a time when a service is at 90% availability from when it is fully down.
Count-based Availability Metrics
Another common way of measuring availability, and the one that I am most familiar with, is to use a “Success Rate”. This is computed by dividing successful requests by the total requests:
Unlike the time-based metrics, SR takes into account partial outages. However, for some services, it’s still an imperfect metric:
- For services where usage varies a lot, between users, the metric can be biased. In the case of Google apps, active users can make 1000x more requests than less active users. If a single active user has an issue with their account, these errors will be overrepresented in the count-based metric.
- If a service is down, this might result in different user behavior. For instance, users might give up and make fewer requests, biasing the success rate. It might also result in retries, further biasing the SR, although in a different direction.
- This metric does not account for time at all. This makes it hard to distinguish between cases where there is a constant stream of errors over time, which may not be disruptive to users who can just retry requests, and hour+ outages, which are disruptive.
Given the downsides for both count-based and time-based availability metrics, none of these metrics satisfy the criteria defined above.
Introducing User Uptime
The authors then introduce a metric they call “User Uptime”, a metric that unlike the two metrics above, is both meaningful and proportional.
This metric is calculated as the sum, for each user, of the amount of “uptime” they experienced on the app, divided by the total time spent on the app.
This is similar in concept to the time-based availability metric defined above, except measured on a per-user basis, which is more appropriate in a distributed systems context. This is because it is tenable to measure whether a user was experiencing “uptime” or “downtime”.
Computing User Uptime
The tricky thing about computing this metric is labeling time a user spends using the application as uptime or downtime. The authors provide a few options here, each involving analyzing the time between user requests. For a given user, the time between two successful requests is definitely uptime, and the time between two failed requests is definitely downtime. What about the time between a successful request and a failed request?

The authors posit that in this case, you can take the approach of counting all time until a failed request as successful, or all time “before” a successful a request as failed, and both achieve the same outcome. Another approach could be splitting the time in half, counting half as uptime and the other as downtime.
Why is this proportional and meaningful?
Meaningful
Unlike the count-based success rate metric, this metric is meaningful because it measures the amount the time that the application was unavailable to users. If there is an outage, for instance, changes in client behavior (issuing lots of retries, or giving up), don’t influence the metric.
Proportional
Unlike the time-based availability metrics, this metric is proportional to the user-perceived availability. With the original time-based availability metrics, there is no indication of how many users were affected by an outage. For instance, an outage during peak hours is not distinguished from an outage at a time when fewer users use an application in time-based metrics, but would be in the user-uptime metrics.
Performance
The authors performed an experiment in which they compared Success Rate (count-based) metric to the user-uptime metric. In this experiment, they ran traffic for an hour, and for a 15 minute period, simulated an outage. Failed requests would result in a retry.
The user-uptime metric accurately measured the system as having 75% uptime, while the success rate resulted in a lower number, demonstrating the higher accuracy of this number.
Making it Actionable: Windowed User Uptime
A problem alluded to earlier with both time-based and count-based availability metrics is that over a longer period of time, it is hard to distinguish between flakiness, for instance, a constant stream of errors, from outages (ie. a 6-hour long outage every quarter). User-uptime does not solve this problem either, as at the end of the day, we still just have a single number to look at to assess availability over the last N days.
To address this, the authors propose “Windowed User-Uptime”. Windowed User-Uptime is a measure of, given a bunch of time durations, the worst of those time durations over a longer time period. So, given time durations such as “1 minute”, “1 hour”, “1 day”, etc, the windowed user-uptime over a quarter will give us the worst minute of user uptime over that quarter, the worst hour, and worst day.
From the paper:
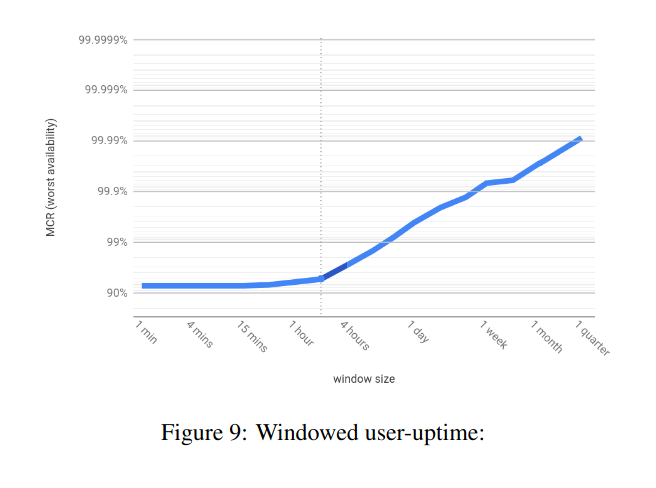
Because this metric provides insight on smaller timescales, this allows teams that use this to dig into windows of particular bad availability, and on a longer-term basis, actually track if the team is getting better at removing the higher impact outages. And especially because in the implementation that the authors discuss, they keep a mapping of which window was the worst for each time duration, they can dig in and see what was going on then.
Applications
The authors describe how Google adopted this new metric, which they used alongside Success Rate, and describe a few examples that demonstrate how it gave them better insight into their systems.
One bad customer
In one of the examples, the authors describe a scenario that due to one heavy customer behaving in an unusual way, the success rate for the overall service dropped significantly. The user-uptime metric did not, because it did not suffer from the same bias as success rate. From this divergence, the authors were able to identify that this SR drop was probably due to a small number of customers, and then were able to dig into charts they had that were specific to heavy users.
The two incident case
In another situation, both the success rate and user-uptime of Google apps dropped for a significant amount of time. This initially indicated a single cause of this drop in performance. However, by lining up the times on a graph, the user-uptime recovered before the success rate did. This divergence in the two metrics suggested that there might be a second cause to investigate.
Further Questions
The main thing I’m still curious about having read this paper is to learn more about cases in which switching to windowed user-uptime actually drove different behavior on Google’s engineering teams.
While it’s clear from the incidents described above that the insights from the new metric are useful, I’m curious if having the windowed data actually drove Google to work prioritize projects that they would not have otherwise.
Conclusion
Overall, this was a really interesting paper to read. It definitely changed my perspective on how to measure availability. Both success rate (count-based), and MTTR/MTTF (time-based) metrics are imperfect and can be biased, so it’s important to think about what you really care to measure from the perspective of your application. This requires taking into account the application’s behavior, client behavior during outages, and other information about your particular application.