Last week, I started learning Rust, and published a post about the “ownership” system. One of the places where Rust’s ownership system really shines is in threading and concurrency. Kevin and I decided to dig into this more on Friday, and did some work on the dining philosophers problem.
In this post I’ll be covering what we learned, and how the Rust compiler saves you from some scary concurrency issues.
What is Concurrency?
So, for starters, what is concurrency?
Concurrency is the process of breaking a program down into units that can be executed in any arbitrary order. The main primitive that is used in most concurrent programming is the “thread”. A thread is a block of instructions that must be executed in order. A single computer program can create many different threads, which themselves will execute in an undetermined order.
Why might you want concurrency?
Writing code in a program without full control over what order the code runs in adds complexity, and makes code much harder to read. So there’d be some good reasons for doing so.
The first reason is to take advantage of systems with multiple processors. In order to do this, a program needs to be written in units that can be run independently, and threads are a great way to accomplish this.
Even if your system only has a single processor, there are still good reasons to use threads. If your program spends a lot of time waiting around, for instance, to make network requests, you might want to pause the thread that is waiting and switch to a thread that is ready to do work.
Different Types of Threading
There are two main ways programming languages implement threading:
- OS threads
Most modern operating systems have native support for threads. In Linux, for instance, threads are essentially processes that share some memory with the parent process that created them. Programming languages that have APIs for creating OS-level threads that can be accessed by running programs. Depending on the API, certain pieces of data can be shared between the parent process and the thread being spun off. Once the thread has been created, it is up to the operating system to schedule when the thread will run, and what resources will be allocated to it.
- Green Threads
Many programming languages have libraries that support software-defined and managed threads, commonly called “green threads”. Rather than actually creating a new process on the system and yielding control to the operating system, green threads don’t actually create any new OS construct They simply give programmers a thread-like interface where in which units of execution can be defined. The process of scheduling these green threads is up to the threading library and the developer themselves, rather than the operating system. The advantage of these is that they are far cheaper to create than new OS threads, as they don’t actually create any new OS resources, and still provide thread-like behavior. The downside is that in order to take advantage of multiple cores, OS-level threads must be used as well (see this for more detail).
Back to Rust
Alright, so that aside, the Rust standard library provides support
for OS-level threads, but not green threads, for which you need to include
third party libraries. Threads can be used fairly simply using the thread::spawn API. I’ll be going through
several examples of code blocks that use this, but here’s a simple example that prints
a string inside of a spawned thread:
use std::thread;
fn main() {
thread::spawn(|| {
println!("Hello from a thread!");
});
}
The main thing to note here is thatt
we are passing a closure to thread::spawn().
This is how anonymous functions work in Rust.
To demonstrate that threads create new OS-level threads, let’s take the following:
// concurrency-bp
use std::{thread, time};
fn main() {
let duration = time::Duration::from_millis(3000);
println!("Main thread");
let handle = thread::spawn(move || {
println!("Inner thread 1");
let handle2 = thread::spawn( move || {
println!("Inner thread 2");
thread::sleep(duration);
});
handle2.join().unwrap();
thread::sleep(duration);
});
handle.join().unwrap();
thread::sleep(duration);
}
Don’t worry too much about the move keyword, I’ll be
explaining this in more detail later. This code simply
spawns a thread, and from that thread, spawns another thread.
They both print something and spend some time sleeping.
The join() function on a thread indicates to the caller
that they should block on the thread completing.
When running this program–we can see that two new threads get created, with the same parent process of ‘./target/debugging/concurrency-bp`.
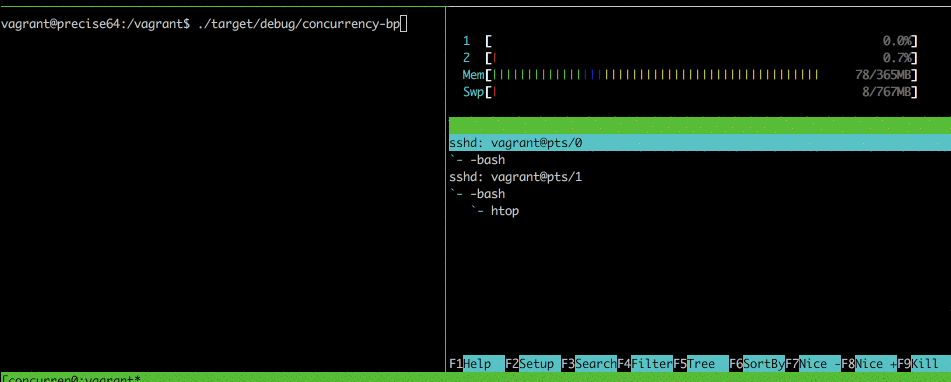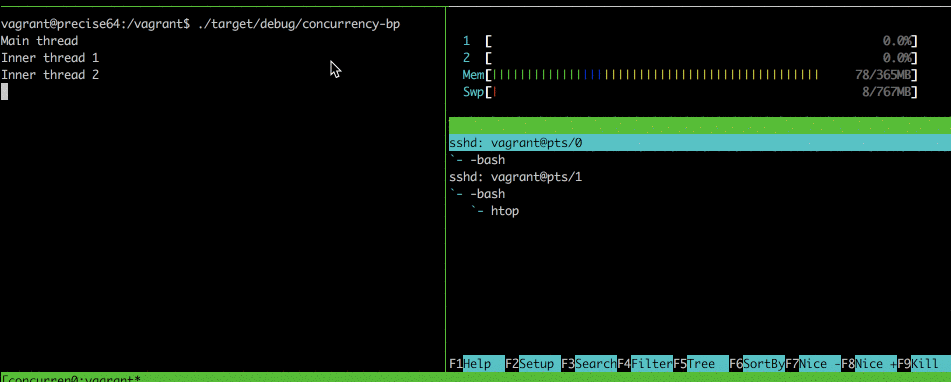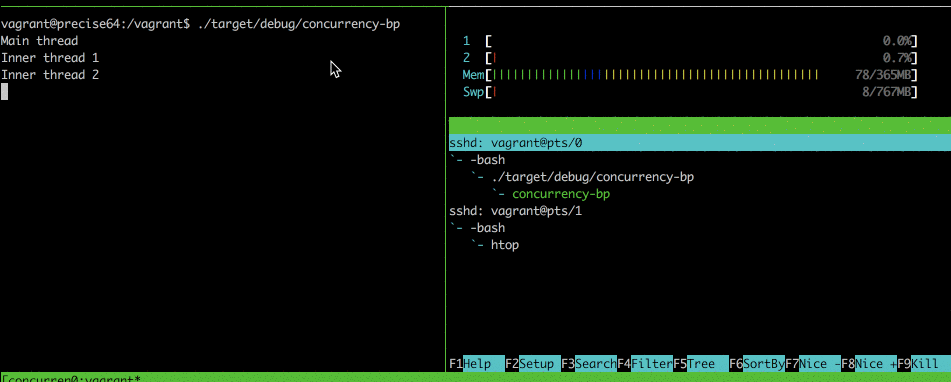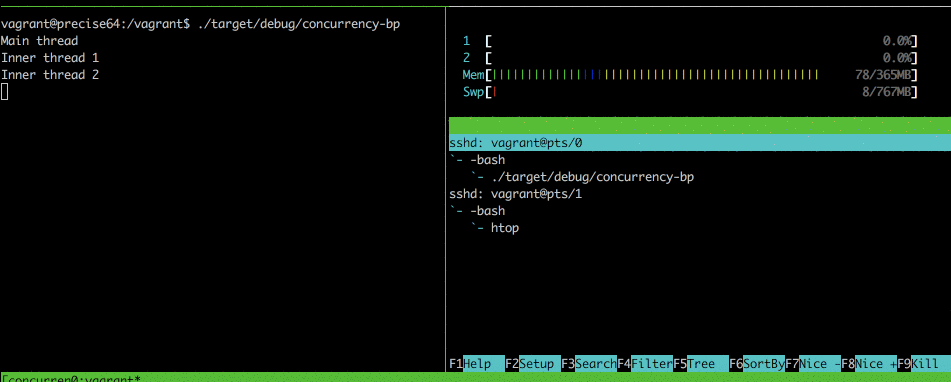
Important: Note that the the parent of the “Inner thread 2” is the main process, rather than “Inner thread 1”. This is a very important detail, because it means that if Inner Thread 1 terminates, the OS does not kill Inner Thread 2. This is not the case with the parent process, where if the parent process were to die, both Inner Threads 1 & 2 would be killed.
Let’s share some data!
Alright, let’s try doing something a little bit more interesting and use some shared data in a thread!
The following code spawns a thread that appends a value to a vector:
// invalid
use std::thread;
fn main() {
let mut v = vec![1,2,3];
thread::spawn(|| {
v.push(4);
});
}
Let’s run it:
$ cargo run
...
closure may outlive the current function, but it borrows `v`, which is owned by the current function
...
Alright, that didn’t work! Let’s unpack the error a little bit. As I discuss in my last blog post,
in Rust, after variables go out of scope, the memory that is allocated to them is deallocated and
returned to the operating system. So if the v in the enclosing scope goes out of scope, it will
be deallocated. So, at the end of main, v would be deallocated. As discussed in the previous section,
it’s totally possible for a thread to continue running beyond the scope of enclosing scope, and if
that was the case, the v in v.push() would be referencing invalid memory.
So, by giving us this compile-time error, the Rust compiler just saved us from a nasty memory access runtime error!
The move keyword
An important detail in the last example is that when we call v.push() in the context
of the thread, ownership of v is still in the enclosing scope. v.push()
actually implicitly does a mutable borrow of v.
If we wanted to move the ownership of v to the thread, Rust has a handy construct
for that, the move
keyword. This keyword takes any variables that a closure references from the enclosing scope
and moves the ownership of these variables to the thread. We can rewrite the
above code block as follows:
// valid
use std::thread;
fn main() {
let mut v = vec![1,2,3];
thread::spawn(move || {
v.push(4);
});
// Can no longer access `v` here.
}
It works! The downside of doing this is that once ownership has been moved to the thread, the variable can no longer be used in the enclosing scope.
Let’s make this more complicated by creating more than just one thread:
// invalid
use std::thread;
fn main() {
let mut v = vec![1,2,3];
for i in 0..10 {
thread::spawn(move || {
v.push(i);
});
}
}
$ cargo run
...
Capture of moved value: `v`
...
Alright, this is clearly not ok. This is a little bit of a confusing
error, but what’s going on here isn’t that different to what happens
with ownership in a non-threaded context. What’s going on basically
is that on the first iteration of the loop, the ownership is transfered
from v to the first the thread. On the second iteration of the thread,
we attempt to move ownership from v to the second thread, and it fails,
because we’ve already moved the ownership of v to the first thread.
It’s similar to doing something like this:
// invalid
let mut v = vec![1,2,3];
let a = v;
let b = v;
...
in a non-threaded context.
This is very problematic in the threading context. If multiple threads had ownership of the same data, as soon as one of those threads completed, the memory storing that vector would be deallocated, and the other threads would begin to read invalid memory.
Again, the Rust compiler saves the day and prevents a nasty concurrency error!
Lifetimes to the rescue
I’m going to walk through one final concurrency issue before I talk about solutions to these issues.
Let’s take the following code example, in which we pass a mutable reference down to a function that creates a thread:
// invalid
fn inner_func(vref: &mut Vec<u32>) {
thread::spawn(move || {
vref.push(3);
});
}
fn main() {
let mut v = vec![1,2,3];
inner_func(&mut v);
}
If you read the previous examples, this code seems a little suspect.
As we discussed earlier, threads can last longer than the enclosing scope.
If main terminates and v goes out of scope, the memory will be cleaned up.
Trying to do anything with mutable references to it will then result in memory errors.
However, we aren’t breaking any ownership rules here.
We are moving the mutable reference vref to the thread when we create the thread,
which then calls .push().
Rust is still able to pick up on this:
$ cargo run
...
explicit lifetime required in the type of `v`
lifetime `'static` required
...
When references are passed down into functions, the value that is being referenced must “live longer” than it’s use in the function that it is passed to.
Now, that is the case with inner_func–the vector
v does live longer than the function call to inner_func.
However, the Rust compiler is smart enough
to recognize that ownership of vref is passed to a closure
that could potentially live longer than main, and since that
is the case, vref must comply with the “static” lifetime.
There are two ways for a value to comply with the static lifetime. String literals by
default have a 'static lifetime, and any values declared with the static keyword
are as well. This can be done like so, static NUM: u32 = 3. Our vector does not
have a 'static lifetime, and therefore, this won’t work.
Yet again, using lifetimes this time, the Rust compiler prevents a concurrency bug!
Solutions
So far, I’ve given a bunch of examples of things that you can’t do in Rust with regards to concurrency. But what are the solutions to some of these problems?
To start with the problem of having a number of threads mutating a single vector, the reality is that cannot have multiple threads take ownership of the raw vector. Rust does, however, have other constructs for sharing data between threads.
Enter: Arc & Mutex
The main structure for sharing data between threads is Arc.
Arc is a reference counter and allows multiple threads to take ownership of some piece of data. The reference counting
behavior of Arc ensures that the data gets cleaned up after all ‘owners’ of the data have finished executing.
The Mutex is another important structure that allows you to perform
atomic operations within each thread. In order to use the data in the structure, you must call .lock() on the mutex.
As long as one thread has the mutex locked, other threads will be blocked.
Here’s how we would accomplish adding values to a vector in threads, using Arc and Mutex:
// valid
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let v = Arc::new(Mutex::new(vec![1,2,3]));
for i in 0..3 {
let cloned_v = v.clone();
thread::spawn(move || {
cloned_v.lock().unwrap().push(i);
});
}
}
When .clone() is called on the Arc, it increases the reference count, and grants ownership
to the data to enclosing scope. When all references are out of scope, the data referenced inside of the Arc
will be cleaned up.
Mutex and Arc are used with generic types, so you they can be used with any type, not just Vec, as
they are in this example (there is an asterisk to this, see this page
for more detail).
Conclusion
If my last post didn’t sell you on borrow/ownership system that Rust provides, hopefully this one does! Concurrency adds a lot of complexity to applications, and having the Rust compiler to help you avoid entire classes of bugs is incredibly helpful.
I also want to give another shoutout to Kevin Martin for helping me understand this stuff!